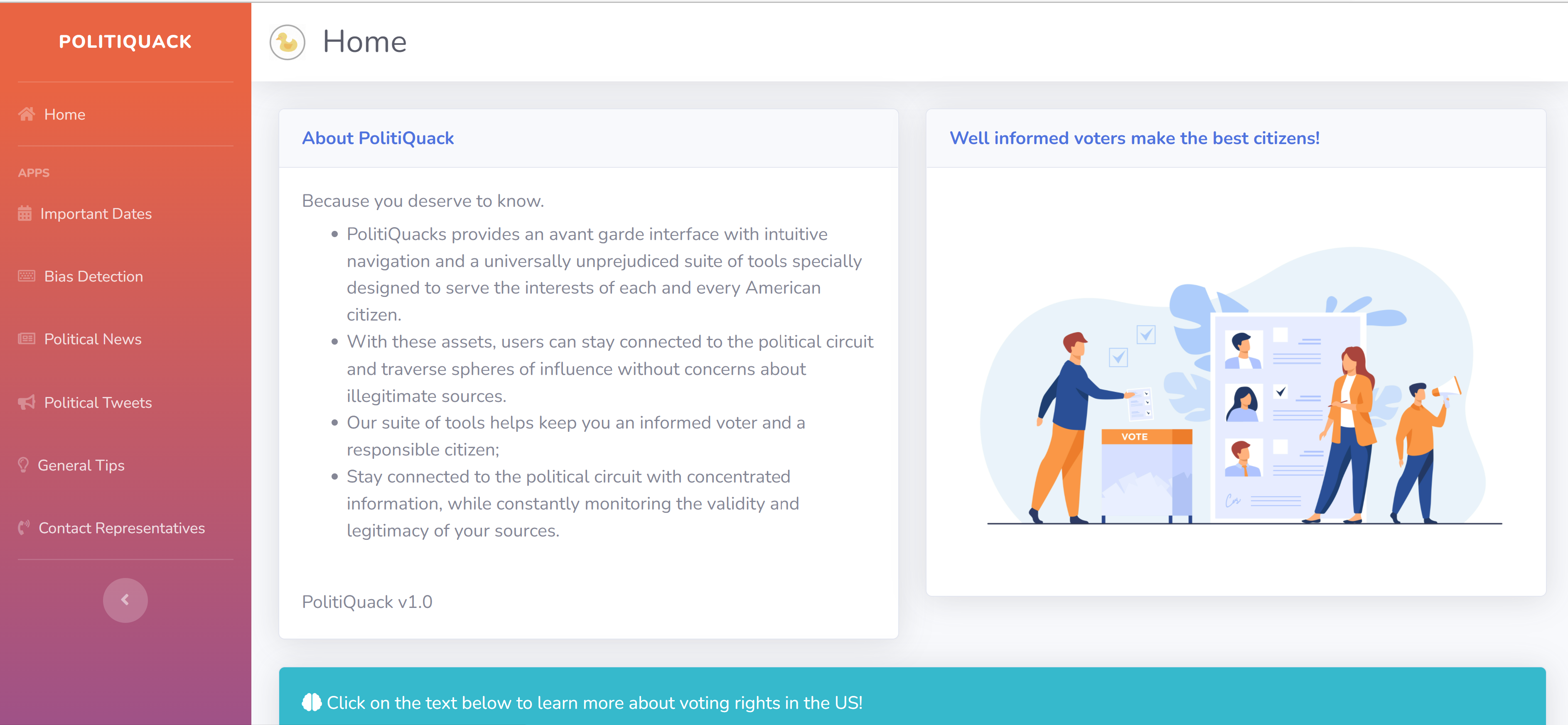
PolitiQuack
PolitiQuack is a multifaceted interface that seeks to concentrate relevant, reliable data regarding the US 2020 Presidential Election. The features offered include a Fake News Detector, unique party-specific news and updates, FAQs and voter tips, as well as a customized state-wise representative contact map.
Check out our codebase, which includes more information about the project: https://github.com/Peter-Feng-32/PoliticalDashboard
Check out our Fake News Detection notebook: https://colab.research.google.com/drive/1rMUXdFfmRvFZb-CvWPSAvzNEUUhH05gb
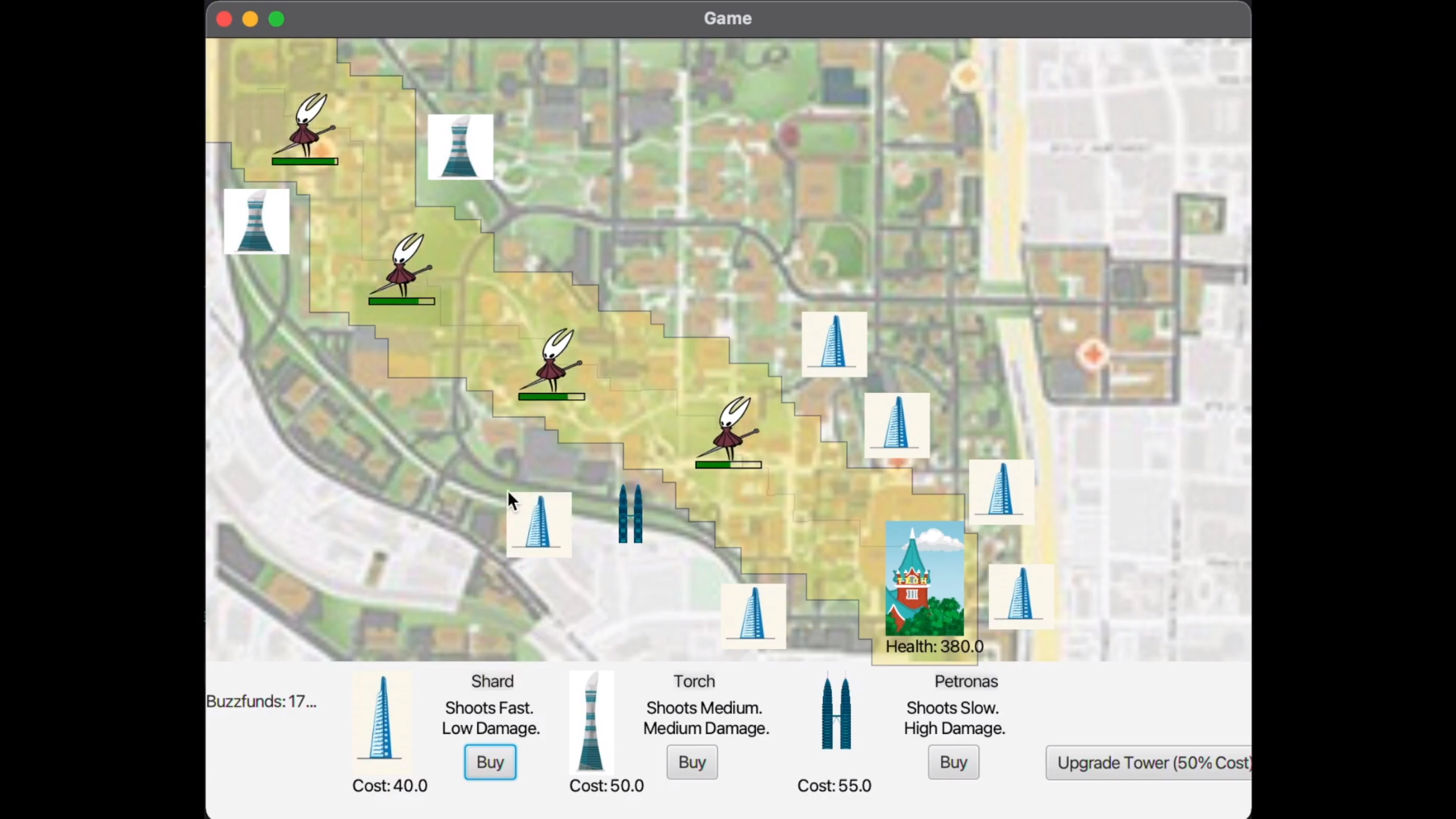
Tech Defense
Tech Defense is a tower defense game built with Java and JavaFX, particularly using the FXML and FXGL libraries. Following the Agile Developmental Process, my team and I incorporated elements of procedural generation for random paths and multi-threading to run processes simultaneously.
Check out a demo video for our game: https://www.youtube.com/watch?v=4uMuu8ix6Vk
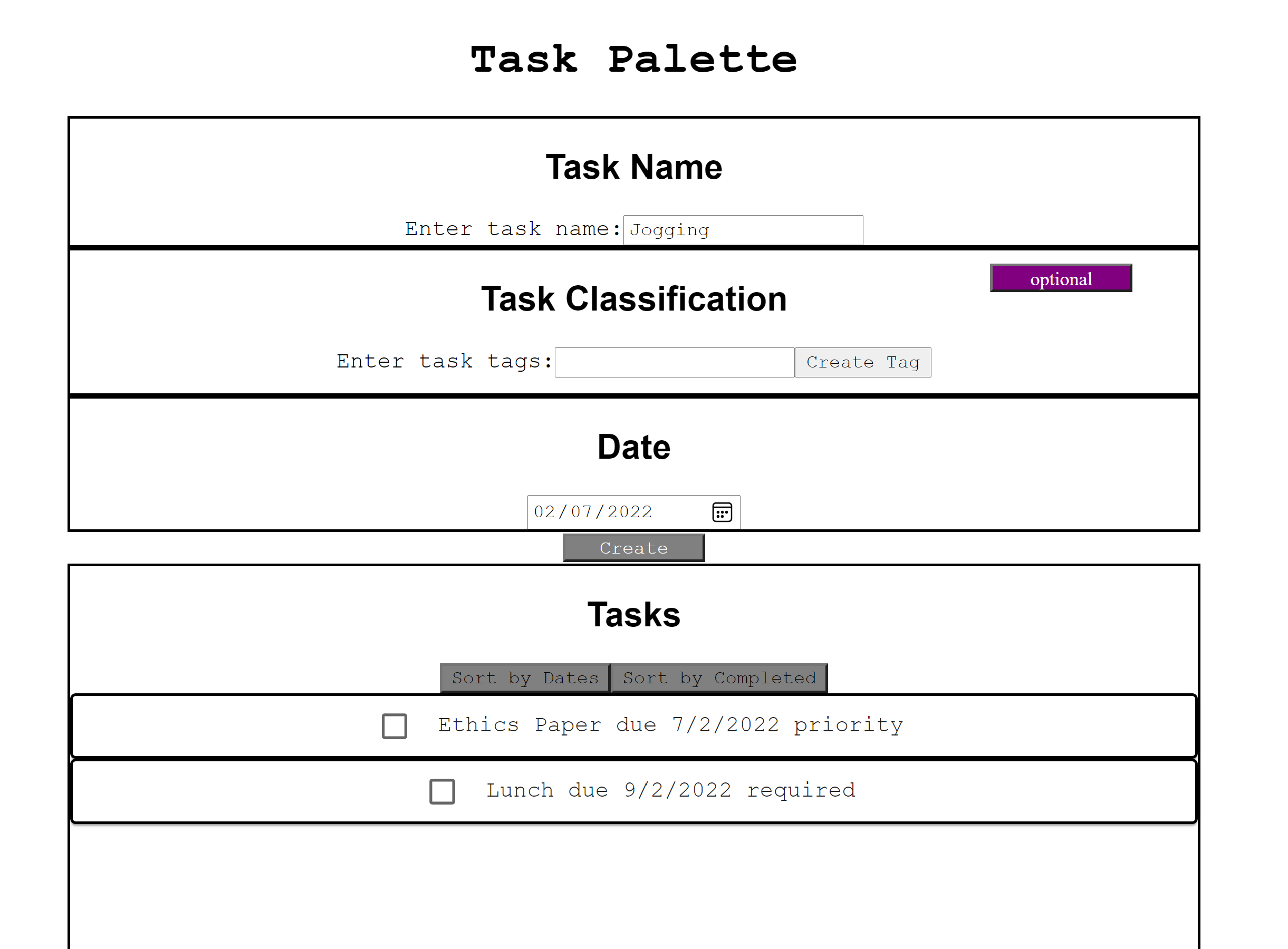
TaskPalette
Built a task to-do list dashboard using React, Javascript, and TypeScript. Individual tasks are assigned to a due date and can be associated with custom tags. Registered tasks can be sorted based on earliest due date, completed status, or both. HTML/CSS for style.
Check out my codebase: https://github.com/aditya-kumaran/fall2021-dev-takehome
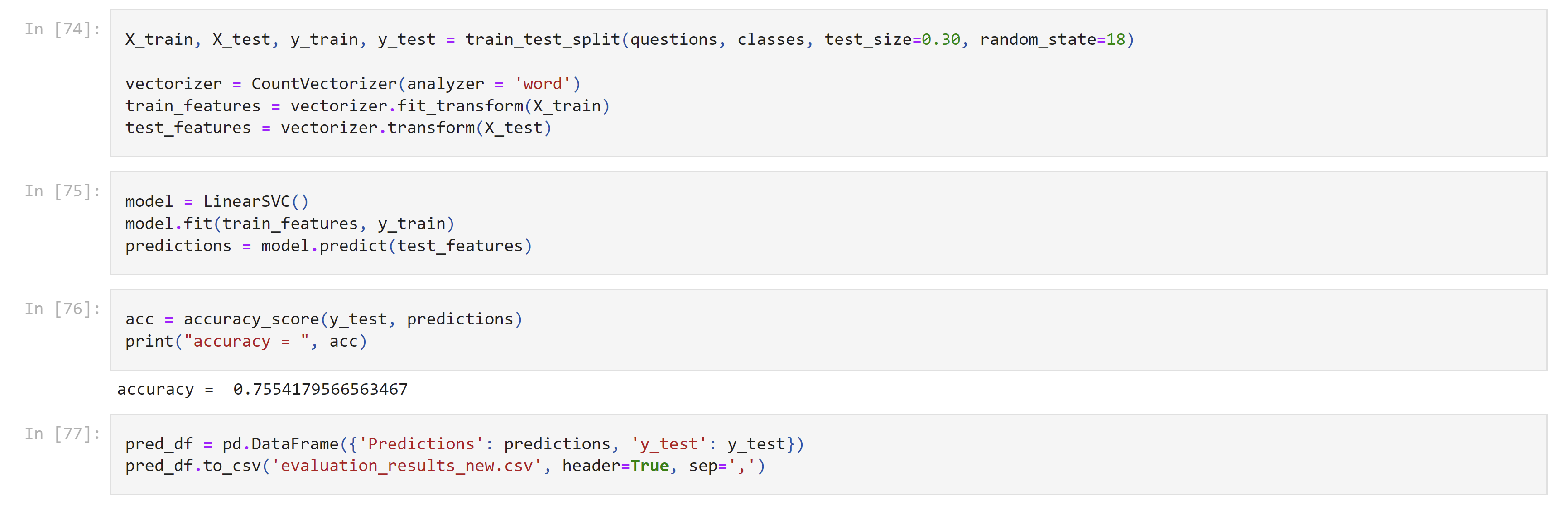
NLP QA Classifier
Built, trained, and tested an NLP classifier to recognize intent of question-style input dataset and accordingly sort into classes. Used CountVectorizer from scikit-learn to vectorize individual words and map their frequency to classes. Modeled through LinearSVC. Analyzed through iris dataset and sklearn metrics. Further documentation available in pdf form in repository.
Accuracy according to sklearn and iris dataset = 75.54%
Check out my codebase: https://github.com/aditya-kumaran/vectorClassifier
MasterClassers
Created a custom website to share entertainment-centric movie reviews, classifying entries into a hierarchy of classes, different genres, and a score out of 10. Provided both spoiler-free and post-watch reviews for each entry. Added option for viewers to contact and request movies to be reviewed. Over 100 movies personally reviewed in the database, being published iteratively using a specialized Bash script.

Check out the website here: https://aditya-kumaran.github.io/MasterClassers/
Check out my codebase: https://github.com/aditya-kumaran/MasterClassers
EMADE
Used the Evolutionary Multi-objective Algorithm Design Engine to evaluate data sets using genetic algorithms and plot the pareto optimal individuals. Set up MySQL Server to run master process; further applied customized evaluation functions to individuals in a database, using Machine Learning algorithms as primitives. Worked with both the Modules and NLP sub-teams, specifically on visualization of pareto indivduals and autopsy of MOGP results relative to BiDAF ML models on the SQuAD dataset respectively. Interfaced with HPC through the PACE supercomputer for faster evolutionary runs and collaborative simulations.
Project files are confidential under student-honor NDA.
Sentiment Analysis of Hotel Reviews Dataset
Discerned the sentiment of hotel review text data with 515,000 reviews compiled from Booking.com concering 1493 luxury hotels across Europe, using various established NLP techniques. Performed data cleaning and pre-processing by removing stopwords, lemmatization, and using NLTK library’s Vader analysis. Feature selection added the original RelativeWordCount feature, and models used TF-IDF, Bag of Words, and Word2Vec embeddings for Multinomial Naive Bayes, RandomForest, SVM, and Logistic Regression to classify reviews according to positive or negative sentiment. Analyzed results with 6 metrics, performed hyperparameter tuning to fine-tune results.
Dataset: https://www.kaggle.com/datasets/jiashenliu/515k-hotel-reviews-data-in-europe
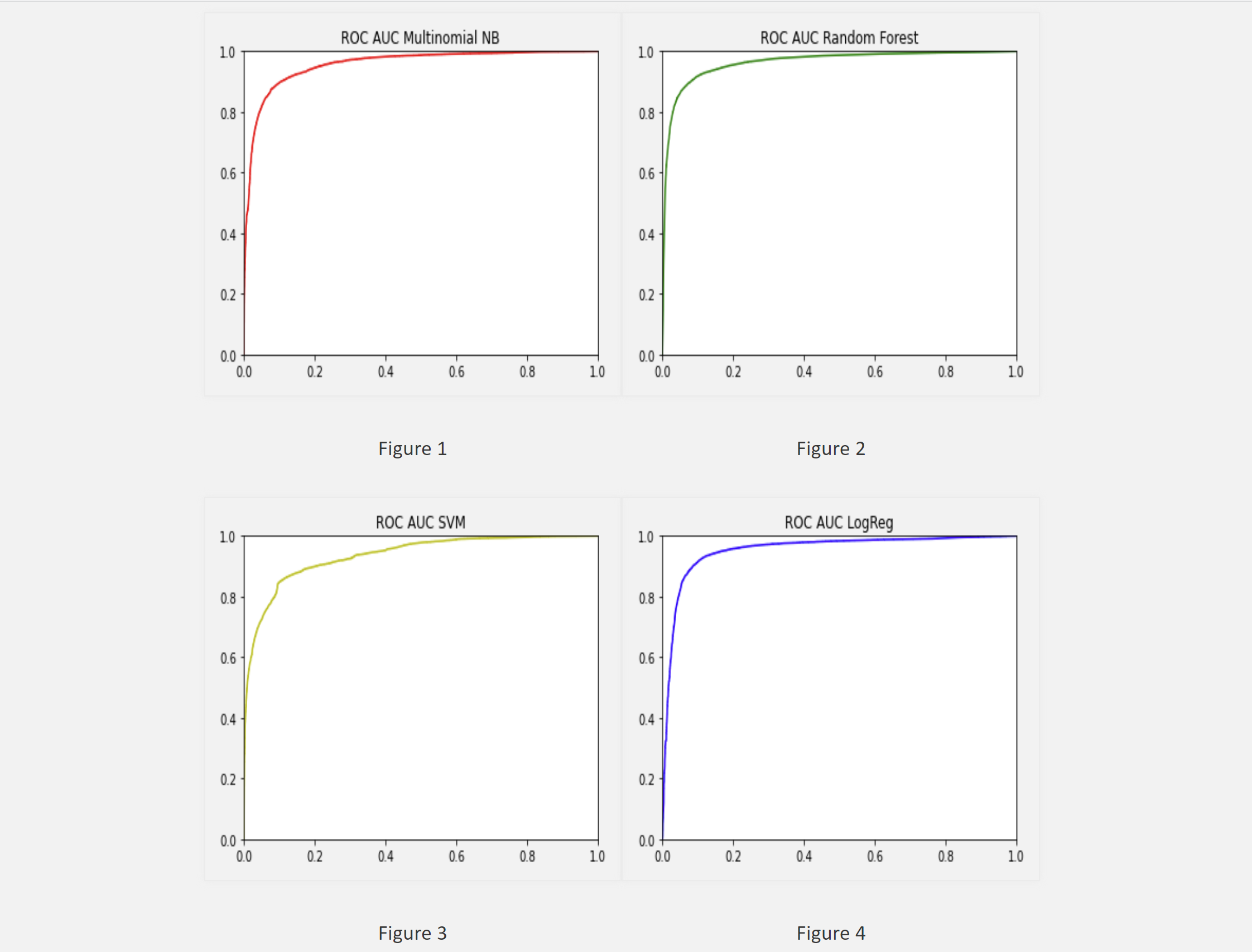
Project Report: https://github.gatech.edu/pages/jkim3663/cs4641-project.github.io/final.html
Good Words: Bad Words:


Project Video Summary: https://www.youtube.com/watch?v=OvUOEI-oxD4
Georgia Tech Student Government Association
Rebuilt legacy JacketPages application, used for submission of monetary bills and resolutions for the entire Georgia Tech student body; identified inoptimal features to be reimplemented and coordinated tasking. As Project Manager, recruited and managed 5-member team of undergraduate and graduate SWE developers. Worked with Directors to negotiate approval from Dean Stein to send survey emails to a student body listserv.
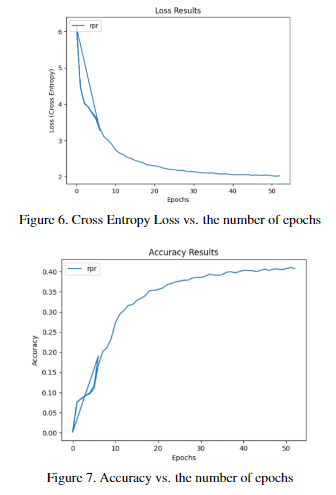
Deep Philharmonics - Music Generation
Created an Deep Learning music generation pipeline by tuning and re-training 4 open-source ML models to produce an original song given an input song (vocals and instrumental) and target voice sample. Fine-tuned Demucs for waveform separation, Spotify’s U-Net and attention-based BasicPitch for audio transcription, and Google’s transformer model for music generation. Calculated cross-correlation between original and output tracks using FFT convolutions as a similarity metric.
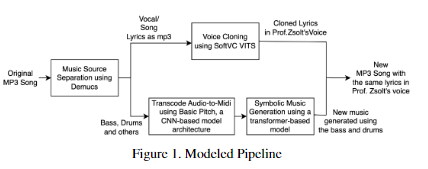
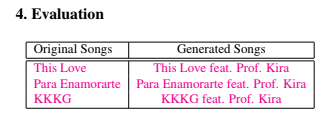
Project Report: https://drive.google.com/file/d/1R4FMGbaWnWtzGI37dMBMfv5RyDgHpGX2/view?usp=sharing
Generated samples can be found in the report (Evaluation section).
Dynamic Movie Recommendation Systems - Temporal GNNs
Implemented and evaluate Heterogeneous Graph Trans- formers (HGT) and Temporal Graph Network (TGN) models on the Movie- Lens100k dataset for temporal recommendations to support changing preferences and new users, performing necessary preprocessing steps. Propose new variant of temporal HGT to improve performance.
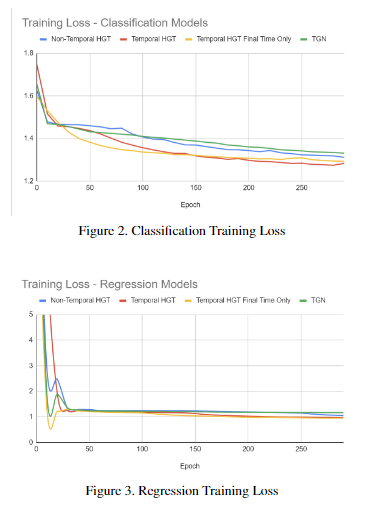
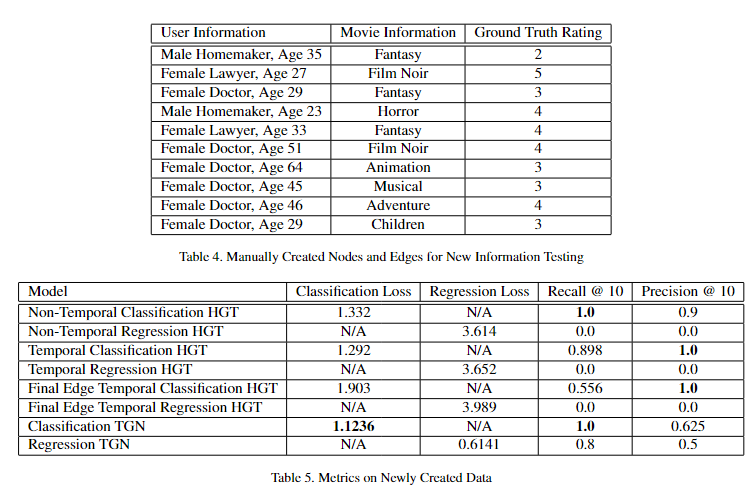
Project Report: https://drive.google.com/file/d/11sztp_fEgl3_SZQacRu1gy47rqio3y-M/view?usp=sharing
Check out my code: https://drive.google.com/drive/folders/15FVWOEq5oDMdwr_T4bk__HoQxbVutwQo?usp=sharing
Is Your Essay Ivy Material? - Essay Evaluation
Explored the ability of LLMs to classify college essays by
university acceptance, trying to detect logical harmony in a
generally abstracted task. Discovered that while the lack
of a large data corpus does limit unsupervised clustering
algorithms, there are valuable quantitative and qualitative
motifs uncovered by LLMs on the supervised learning and
in-context learning classification task respectively.
Examined the effectiveness of finetuning pretrained autoencoder models (BERT) with strong semantic
understandings to identify commonalities between accepted essays, compared to baselines of
RobertaForSequenceClassification, unsupervised clustering algorithms such as KMeans and Hierarchical
Agglomerative
Clustering, and a few-shot chain-of-thought prompting approach, which enables the language model to
learn from a
few gold-standard examples.

Project Report: https://drive.google.com/file/d/1tM0uKSgT5wxlhREY-FQz1DFWOft5UrgP/view?usp=sharing
Check out my code and data: https://drive.google.com/drive/folders/16EkzS_DfS1zUWHD1SNBaspUC4L9vTZnV?usp=drive_link
Check out my project video: https://www.youtube.com/watch?v=8VCB8Vb-ueg